Train Agents
RL Quickstart
Train agents with reinforcement learning using GRPO
Train agents to perform better on specific tasks using GRPO (Group Relative Policy Optimization).
The included 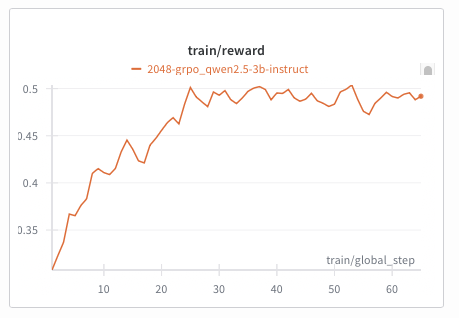 Qwen-2.5-3B agent training on the text-2048 environment using GRPO
Qwen-2.5-3B agent training on the text-2048 environment using GRPO
Quick Start
Prerequisites
- GPU with 24GB+ VRAM (A100, RTX 4090)
- Python 3.12+
- HUD API key (set
HUD_API_KEYenvironment variable)
Installation
Train 2048 Agent
1
Build Docker Image
2
Start vLLM Server
3
Run Training
train_2048.py script trains a 3B model on the 2048 game. Training takes ~30 minutes for 100 steps.
Qwen-2.5-3B agent training on the text-2048 environment using GRPO
How It Works
GRPO trains by comparing multiple attempts on the same task:Configuration
Training uses YAML configs to map agent tools to MCP tools.:Custom Training
Monitoring
HUD Dashboard
View training progress and traces at app.hud.so:- Real-time screenshot and setp viewing
- Tool call traces for each trajectory
- Reward distribution across generations
Weights & Biases
For detailed ML metrics:Resources
- Example Training Script
- HUD VF Gym - Verifiers integration